A bookmarklet is a small JavaScript program that can be saved as a bookmark in your browser. This particular bookmarklet allows you to open a new network in Local Citation Network directly when surfing many journals' websites (e.g. Nature, Science, Lancet, …) with the advantage that the original order of references is preserved. Save the following link as a bookmark (e.g. by dragging it to your bookmarks bar) and then click on it when reading an article:
Open in Local Citation Network
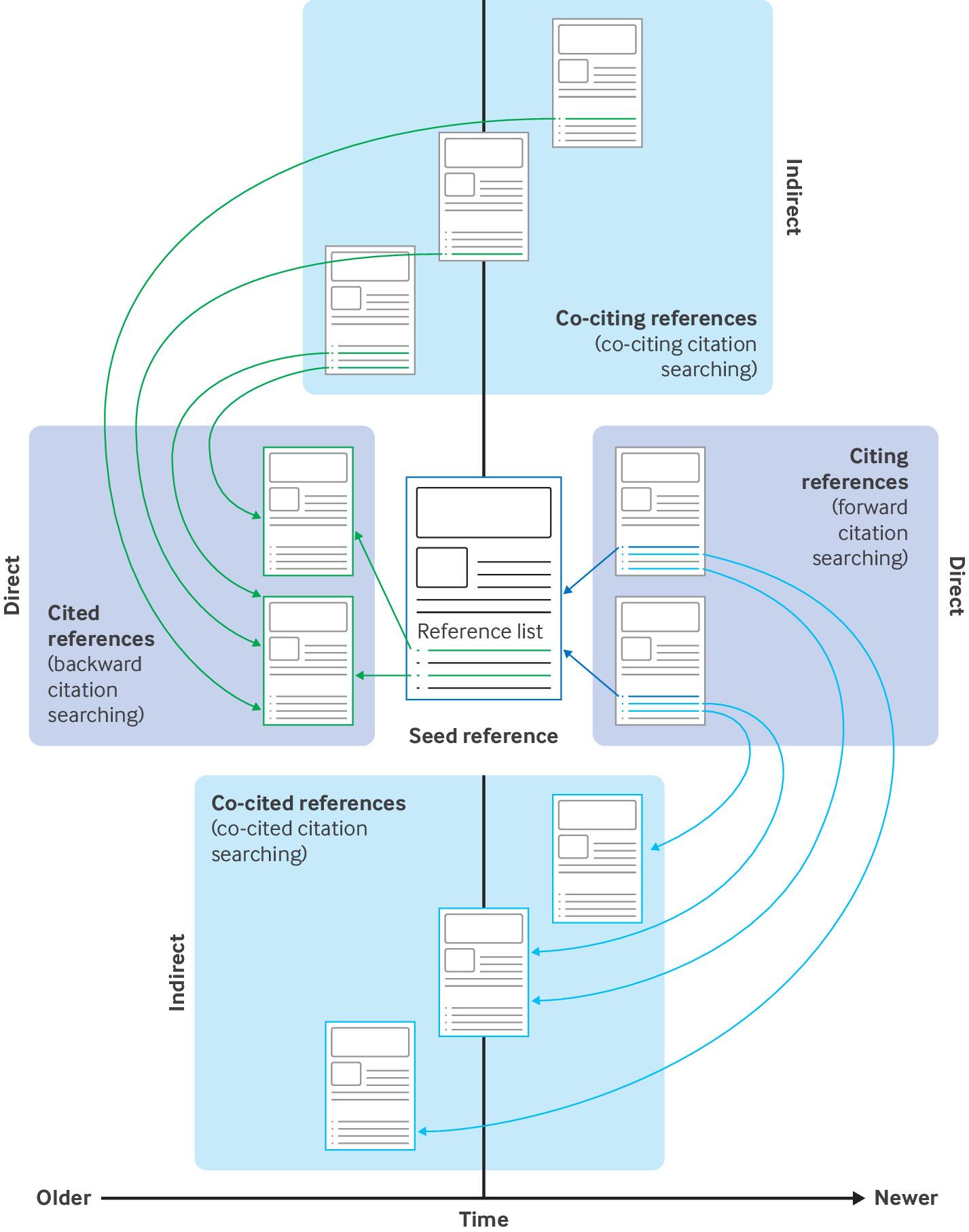
The bookmarklet is particularly useful when you want to use Local Citation Network as a 'second screen' when you are reading a paper, showing you its references in the correct order and allowing you to view their abstracts and to identify seminal articles as well as additional suggested articles. When using the bookmarklet, the reference list is scanned directly from the website, thus preserving the original order of references.
PubMed is also supported by the bookmarklet, giving access to a vast number of biomedical papers. Before clicking the bookmarklet, scroll down on the paper page (e.g. this one) and click "Show all X references". Make sure to use the OpenAlex (OA) or Semantic Scholar (S2) APIs , as they are supporting PubMed IDs (PMIDs).
Unfortunately, not all journals' websites are supported. If you know how to code, check out the code of the bookmarklet on GitHub and extend it to support more journals! In this light it might be worth updating the bookmark in your browser from time to time to benefit from possible improvements.